Datenanalyse Teil I#
Natalie Widmann#
Wintersemester 2024 / 2025
Datenanalyse und -verarbeitung in Python#
Ziele#
Verständnis der Analyseschritte im Datenjournalismus
Eplorative Analyse von strukturierten Daten
Grundkenntnisse bei der Visualisierung von Daten
Kennenlernen von Python Package Pandas
Was sind Daten?#
Strukturierte Daten#
Strukturierte Daten sind gut organisiert und so formattiert, dass es einfach ist sie zu durchsuchen, sie maschinell zu lesen oder zu verarbeiten. Das einfachste Beispiel ist eine Tabelle in der jede Spalte eine Kategorie oder einen Wert festlegt.
Unstrukturierte Daten#
Im Gegensatz dazu sind unstrukturierte Daten nicht in einem bestimmten Format oder einer festgelegten Struktur verfügbar. Dazu zählen Texte, Bilder, Social Media Feeds, aber auch Audio Files, etc.
Semi-Strukturierte Daten#
Semi-strukturierte Daten bilden eine Mischform. Beispielsweise eine Tabelle mit E-Mail Daten, in der Empfänger, Betreff, Datum und Absender strukturierte Informationen enthalten, der eigentliche Text jedoch unstrukturiert ist.
Was sind Daten?#

Pandas#
Pandas ist ein Python Package und ist abgeleitet aus “Python and data analysis”.
Pandas stellt die Grundfunktionalitäten für das Arbeiten mit strukturierten Daten zur Verfügung.
Installation von Python Packages#
Packages die von der Python Community zur Verfügung gestellt werden, müssen vor der Verwendung installiert werden.
Dafür können Packagemanager wie pip verwendet werden.
Weitere Tipps für die Installation von Python Packages in Windows, Linux und Mac gibt es hier.
In Jupyter Notebooks können Packages wie folgt installiert werden:
# Install a pip package im Jupyter Notebook
import sys
!pip install pandas
!pip install openpyxl
Requirement already satisfied: pandas in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (2.2.3)
Requirement already satisfied: numpy>=1.23.2 in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from pandas) (1.26.4)
Requirement already satisfied: python-dateutil>=2.8.2 in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from pandas) (2.8.2)
Requirement already satisfied: pytz>=2020.1 in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from pandas) (2023.3.post1)
Requirement already satisfied: tzdata>=2022.7 in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from pandas) (2023.3)
Requirement already satisfied: six>=1.5 in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from python-dateutil>=2.8.2->pandas) (1.16.0)
Requirement already satisfied: openpyxl in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (3.1.5)
Requirement already satisfied: et-xmlfile in /home/natalie-widmann/anaconda3/lib/python3.11/site-packages (from openpyxl) (1.1.0)
import pandas as pd
pd.set_option('display.float_format', '{:.2f}'.format)
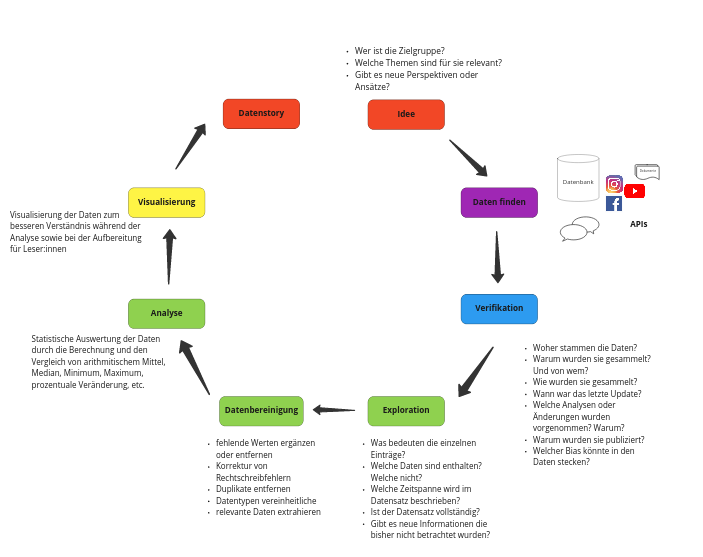
Idee, Daten finden & Verifikation#
Aggregated figures for Natural Disasters in EM-DAT#
Link: https://data.humdata.org/dataset/emdat-country-profiles
In 1988, the Centre for Research on the Epidemiology of Disasters (CRED) launched the Emergency Events Database (EM-DAT). EM-DAT was created with the initial support of the World Health Organisation (WHO) and the Belgian Government.
The main objective of the database is to serve the purposes of humanitarian action at national and international levels. The initiative aims to rationalise decision making for disaster preparedness, as well as provide an objective base for vulnerability assessment and priority setting.
EM-DAT contains essential core data on the occurrence and effects of over 22,000 mass disasters in the world from 1900 to the present day. The database is compiled from various sources, including UN agencies, non-governmental organisations, insurance companies, research institutes and press agencies.
Was ist die Geschichte?#
Mögliche Ansätze / Fragen an die Daten#
Steigt die Anzahl an Naturkatastrophen weltweit?
In welchem Jahr gabe es die meisten Naturkatastrophen?
Welche Länder sind am stärksten von Naturkatastrophen betroffen?
Wie ist die Situation in Deutschland?
Welche Länder sind von Naturkatastrophen betroffen haben aber vergleichsweise geringe Todesfälle?
Welche Naturkatastrophen sind am tödlichsten?
Daten einlesen mit Pandas#
siehe auch:
data_url = "https://data.humdata.org/dataset/74163686-a029-4e27-8fbf-c5bfcd13f953/resource/c5ce40d6-07b1-4f36-955a-d6196436ff6b/download/emdat-country-profiles_2024_12_02.xlsx"
data = pd.read_excel(data_url, engine="openpyxl")
data
| Year | Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | #date +occurred | #country +name | #country +code | #cause +group | #cause +subgroup | #cause +type | #cause +subtype | #frequency | #affected +ind | #affected +ind +killed | NaN | #value +usd | NaN |
| 1 | 2000 | Afghanistan | AFG | Natural | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 | 88473 | 56.51 |
| 2 | 2000 | Algeria | DZA | Natural | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN | NaN | 56.51 |
| 3 | 2000 | Algeria | DZA | Natural | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN | NaN | 56.51 |
| 4 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN | NaN | 56.51 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | VNM | Natural | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 | NaN | NaN |
| 6142 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN | NaN | NaN |
| 6143 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN | NaN | NaN |
| 6144 | 2024 | Zambia | ZMB | Natural | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN | NaN | NaN |
| 6145 | 2024 | Zimbabwe | ZWE | Natural | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN | NaN | NaN |
6146 rows × 13 columns
Datenexploration und -bereinigung#
Überblick über die Daten#
Wie groß ist der Datensatz?
Wie viele Zeilen und wie viele Spalten sind vorhanden?
siehe auch:#
data.shape
(6146, 13)
Die Spaltennamen
data.columns
Index(['Year', 'Country', 'ISO', 'Disaster Group', 'Disaster Subroup',
'Disaster Type', 'Disaster Subtype', 'Total Events', 'Total Affected',
'Total Deaths', 'Total Damage (USD, original)',
'Total Damage (USD, adjusted)', 'CPI'],
dtype='object')
info() für mehr Infos über die Spalten
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6146 entries, 0 to 6145
Data columns (total 13 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year 6146 non-null object
1 Country 6146 non-null object
2 ISO 6146 non-null object
3 Disaster Group 6146 non-null object
4 Disaster Subroup 6146 non-null object
5 Disaster Type 6146 non-null object
6 Disaster Subtype 6146 non-null object
7 Total Events 6146 non-null object
8 Total Affected 4963 non-null object
9 Total Deaths 4359 non-null object
10 Total Damage (USD, original) 2095 non-null float64
11 Total Damage (USD, adjusted) 2059 non-null object
12 CPI 5917 non-null float64
dtypes: float64(2), object(11)
memory usage: 624.3+ KB
describe() zeigt die grundlegenden statistischen Eigenschaften von Spalten mit numerischem Datentyp, also int und float.
Die Methode berechnet:
die Anzahl an fehlenden Werten
Durchschnitt
Standardabweichung
Zahlenrange
Media
0.25 und 0.75 Quartile
data.describe()
| Total Damage (USD, original) | CPI | |
|---|---|---|
| count | 2095.00 | 5917.00 |
| mean | 1716696139.34 | 74.30 |
| std | 8615286125.55 | 11.91 |
| min | 2000.00 | 56.51 |
| 25% | 20000000.00 | 64.09 |
| 50% | 130000000.00 | 73.82 |
| 75% | 801000000.00 | 82.41 |
| max | 210000000000.00 | 100.00 |
Data Cleaning#
Erste Zeile im DataFrame entfernen
Möglichkeit: Slicing
data[1]
| Year | Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 10 | 2000 | Argentina | ARG | Natural | Meteorological | Extreme temperature | Cold wave | 1 | 300 | 15 | NaN | NaN | 56.51 |
| 11 | 2000 | Argentina | ARG | Natural | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | NaN | NaN | NaN | 56.51 |
| 12 | 2000 | Argentina | ARG | Natural | Meteorological | Storm | Lightning/Thunderstorms | 1 | 430 | 1 | NaN | NaN | 56.51 |
| 13 | 2000 | Armenia | ARM | Natural | Climatological | Drought | Drought | 1 | 297000 | NaN | 100000000.00 | 176946395 | 56.51 |
| 14 | 2000 | Australia | AUS | Natural | Biological | Infestation | Locust infestation | 1 | NaN | NaN | 120000000.00 | 212335674 | 56.51 |
data.index
RangeIndex(start=0, stop=6146, step=1)
data
| Year | Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | #date +occurred | #country +name | #country +code | #cause +group | #cause +subgroup | #cause +type | #cause +subtype | #frequency | #affected +ind | #affected +ind +killed | NaN | #value +usd | NaN |
| 1 | 2000 | Afghanistan | AFG | Natural | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 | 88473 | 56.51 |
| 2 | 2000 | Algeria | DZA | Natural | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN | NaN | 56.51 |
| 3 | 2000 | Algeria | DZA | Natural | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN | NaN | 56.51 |
| 4 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN | NaN | 56.51 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | VNM | Natural | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 | NaN | NaN |
| 6142 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN | NaN | NaN |
| 6143 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN | NaN | NaN |
| 6144 | 2024 | Zambia | ZMB | Natural | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN | NaN | NaN |
| 6145 | 2024 | Zimbabwe | ZWE | Natural | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN | NaN | NaN |
6146 rows × 13 columns
Möglichkeit: Drop
siehe auch: Drop
data.drop(index=0)
| Year | Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2000 | Afghanistan | AFG | Natural | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 | 88473 | 56.51 |
| 2 | 2000 | Algeria | DZA | Natural | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN | NaN | 56.51 |
| 3 | 2000 | Algeria | DZA | Natural | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN | NaN | 56.51 |
| 4 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN | NaN | 56.51 |
| 5 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Riverine flood | 1 | 70000 | 31 | 10000000.00 | 17694640 | 56.51 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | VNM | Natural | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 | NaN | NaN |
| 6142 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN | NaN | NaN |
| 6143 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN | NaN | NaN |
| 6144 | 2024 | Zambia | ZMB | Natural | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN | NaN | NaN |
| 6145 | 2024 | Zimbabwe | ZWE | Natural | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN | NaN | NaN |
6145 rows × 13 columns
data = data.drop(index=0)
data
| Year | Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2000 | Afghanistan | AFG | Natural | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 | 88473 | 56.51 |
| 2 | 2000 | Algeria | DZA | Natural | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN | NaN | 56.51 |
| 3 | 2000 | Algeria | DZA | Natural | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN | NaN | 56.51 |
| 4 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN | NaN | 56.51 |
| 5 | 2000 | Angola | AGO | Natural | Hydrological | Flood | Riverine flood | 1 | 70000 | 31 | 10000000.00 | 17694640 | 56.51 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | VNM | Natural | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 | NaN | NaN |
| 6142 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN | NaN | NaN |
| 6143 | 2024 | Yemen | YEM | Natural | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN | NaN | NaN |
| 6144 | 2024 | Zambia | ZMB | Natural | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN | NaN | NaN |
| 6145 | 2024 | Zimbabwe | ZWE | Natural | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN | NaN | NaN |
6145 rows × 13 columns
data.drop(['Year'], axis=1)
#data
| Country | ISO | Disaster Group | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | Total Damage (USD, adjusted) | CPI | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | Afghanistan | AFG | Natural | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 | 88473 | 56.51 |
| 2 | Algeria | DZA | Natural | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN | NaN | 56.51 |
| 3 | Algeria | DZA | Natural | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN | NaN | 56.51 |
| 4 | Angola | AGO | Natural | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN | NaN | 56.51 |
| 5 | Angola | AGO | Natural | Hydrological | Flood | Riverine flood | 1 | 70000 | 31 | 10000000.00 | 17694640 | 56.51 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | Viet Nam | VNM | Natural | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 | NaN | NaN |
| 6142 | Yemen | YEM | Natural | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN | NaN | NaN |
| 6143 | Yemen | YEM | Natural | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN | NaN | NaN |
| 6144 | Zambia | ZMB | Natural | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN | NaN | NaN |
| 6145 | Zimbabwe | ZWE | Natural | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN | NaN | NaN |
6145 rows × 12 columns
Entferne irrelevante Spalten
cols = ['ISO', 'Disaster Group', 'Total Damage (USD, adjusted)', 'CPI']
data = data.drop(cols, axis=0, inplace=True)
---------------------------------------------------------------------------
KeyError Traceback (most recent call last)
Cell In[27], line 2
1 cols = ['Disaster Group', 'Total Damage (USD, adjusted)', 'CPI']
----> 2 data = data.drop(cols, axis=0, inplace=True)
File ~/anaconda3/lib/python3.11/site-packages/pandas/core/frame.py:5581, in DataFrame.drop(self, labels, axis, index, columns, level, inplace, errors)
5433 def drop(
5434 self,
5435 labels: IndexLabel | None = None,
(...)
5442 errors: IgnoreRaise = "raise",
5443 ) -> DataFrame | None:
5444 """
5445 Drop specified labels from rows or columns.
5446
(...)
5579 weight 1.0 0.8
5580 """
-> 5581 return super().drop(
5582 labels=labels,
5583 axis=axis,
5584 index=index,
5585 columns=columns,
5586 level=level,
5587 inplace=inplace,
5588 errors=errors,
5589 )
File ~/anaconda3/lib/python3.11/site-packages/pandas/core/generic.py:4788, in NDFrame.drop(self, labels, axis, index, columns, level, inplace, errors)
4786 for axis, labels in axes.items():
4787 if labels is not None:
-> 4788 obj = obj._drop_axis(labels, axis, level=level, errors=errors)
4790 if inplace:
4791 self._update_inplace(obj)
File ~/anaconda3/lib/python3.11/site-packages/pandas/core/generic.py:4830, in NDFrame._drop_axis(self, labels, axis, level, errors, only_slice)
4828 new_axis = axis.drop(labels, level=level, errors=errors)
4829 else:
-> 4830 new_axis = axis.drop(labels, errors=errors)
4831 indexer = axis.get_indexer(new_axis)
4833 # Case for non-unique axis
4834 else:
File ~/anaconda3/lib/python3.11/site-packages/pandas/core/indexes/base.py:7070, in Index.drop(self, labels, errors)
7068 if mask.any():
7069 if errors != "ignore":
-> 7070 raise KeyError(f"{labels[mask].tolist()} not found in axis")
7071 indexer = indexer[~mask]
7072 return self.delete(indexer)
KeyError: "['Disaster Group', 'Total Damage (USD, adjusted)', 'CPI'] not found in axis"
data
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2000 | Afghanistan | Climatological | Drought | Drought | 1 | 2580000 | 37 | 50000.00 |
| 2 | 2000 | Algeria | Hydrological | Flood | Flash flood | 1 | 100 | 28 | NaN |
| 3 | 2000 | Algeria | Meteorological | Storm | Storm (General) | 1 | 10 | 4 | NaN |
| 4 | 2000 | Angola | Hydrological | Flood | Flood (General) | 3 | 9011 | 15 | NaN |
| 5 | 2000 | Angola | Hydrological | Flood | Riverine flood | 1 | 70000 | 31 | 10000000.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | Meteorological | Storm | Tropical cyclone | 3 | 3747257 | 354 | 2000000000.00 |
| 6142 | 2024 | Yemen | Hydrological | Flood | Flash flood | 1 | 1075 | 40 | NaN |
| 6143 | 2024 | Yemen | Hydrological | Flood | Flood (General) | 2 | 210439 | 62 | NaN |
| 6144 | 2024 | Zambia | Climatological | Drought | Drought | 1 | 6600000 | NaN | NaN |
| 6145 | 2024 | Zimbabwe | Climatological | Drought | Drought | 1 | 7600000 | NaN | NaN |
6145 rows × 9 columns
Einzelne Spalten auswählen und besser verstehen#
siehe auch:
Auf die Werte einer Spalte kann <dataframe>['<spaltenname>'] zugegriffen werden.
data['Year']
1 2000
2 2000
3 2000
4 2000
5 2000
...
6141 2024
6142 2024
6143 2024
6144 2024
6145 2024
Name: Year, Length: 6145, dtype: object
Mehrere Spalten können über eine Liste ausgewählt werden
data[['Year', 'Country']]
| Year | Country | |
|---|---|---|
| 1 | 2000 | Afghanistan |
| 2 | 2000 | Algeria |
| 3 | 2000 | Algeria |
| 4 | 2000 | Angola |
| 5 | 2000 | Angola |
| ... | ... | ... |
| 6141 | 2024 | Viet Nam |
| 6142 | 2024 | Yemen |
| 6143 | 2024 | Yemen |
| 6144 | 2024 | Zambia |
| 6145 | 2024 | Zimbabwe |
6145 rows × 2 columns
columns = ['Year', 'Country', 'Total Events', 'Total Affected']
data[columns]
| Year | Country | Total Events | Total Affected | |
|---|---|---|---|---|
| 1 | 2000 | Afghanistan | 1 | 2580000 |
| 2 | 2000 | Algeria | 1 | 100 |
| 3 | 2000 | Algeria | 1 | 10 |
| 4 | 2000 | Angola | 3 | 9011 |
| 5 | 2000 | Angola | 1 | 70000 |
| ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | 3 | 3747257 |
| 6142 | 2024 | Yemen | 1 | 1075 |
| 6143 | 2024 | Yemen | 2 | 210439 |
| 6144 | 2024 | Zambia | 1 | 6600000 |
| 6145 | 2024 | Zimbabwe | 1 | 7600000 |
6145 rows × 4 columns
Datentypen abfragen und anpassen#
siehe auch:
data.describe()
| Year | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|
| count | 6145.00 | 6145.00 | 4962.00 | 4358.00 | 2095.00 |
| mean | 2011.90 | 1.52 | 950993.11 | 340.69 | 1716696139.34 |
| std | 7.42 | 1.28 | 8392369.40 | 5265.72 | 8615286125.55 |
| min | 2000.00 | 1.00 | 1.00 | 1.00 | 2000.00 |
| 25% | 2005.00 | 1.00 | 1003.00 | 4.00 | 20000000.00 |
| 50% | 2012.00 | 1.00 | 10000.00 | 14.00 | 130000000.00 |
| 75% | 2019.00 | 2.00 | 100552.75 | 49.00 | 801000000.00 |
| max | 2024.00 | 17.00 | 330000000.00 | 222570.00 | 210000000000.00 |
data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6145 entries, 1 to 6145
Data columns (total 9 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 Year 6145 non-null int64
1 Country 6145 non-null object
2 Disaster Subroup 6145 non-null object
3 Disaster Type 6145 non-null object
4 Disaster Subtype 6145 non-null object
5 Total Events 6145 non-null int64
6 Total Affected 4962 non-null float64
7 Total Deaths 4358 non-null float64
8 Total Damage (USD, original) 2095 non-null float64
dtypes: float64(3), int64(2), object(4)
memory usage: 432.2+ KB
for x in ['Total Events', 'Total Affected', 'Total Deaths']:
data[x] = pd.to_numeric(data[x])
#data["Year"] = pd.to_numeric(data['Year'])
data
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 2000 | Afghanistan | Climatological | Drought | Drought | 1 | 2580000.00 | 37.00 | 50000.00 |
| 2 | 2000 | Algeria | Hydrological | Flood | Flash flood | 1 | 100.00 | 28.00 | NaN |
| 3 | 2000 | Algeria | Meteorological | Storm | Storm (General) | 1 | 10.00 | 4.00 | NaN |
| 4 | 2000 | Angola | Hydrological | Flood | Flood (General) | 3 | 9011.00 | 15.00 | NaN |
| 5 | 2000 | Angola | Hydrological | Flood | Riverine flood | 1 | 70000.00 | 31.00 | 10000000.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6141 | 2024 | Viet Nam | Meteorological | Storm | Tropical cyclone | 3 | 3747257.00 | 354.00 | 2000000000.00 |
| 6142 | 2024 | Yemen | Hydrological | Flood | Flash flood | 1 | 1075.00 | 40.00 | NaN |
| 6143 | 2024 | Yemen | Hydrological | Flood | Flood (General) | 2 | 210439.00 | 62.00 | NaN |
| 6144 | 2024 | Zambia | Climatological | Drought | Drought | 1 | 6600000.00 | NaN | NaN |
| 6145 | 2024 | Zimbabwe | Climatological | Drought | Drought | 1 | 7600000.00 | NaN | NaN |
6145 rows × 9 columns
data["Year"] = pd.to_numeric(data['Year'])
y
dtype('O')
data['Year']
1 2000
2 2000
3 2000
4 2000
5 2000
...
6141 2024
6142 2024
6143 2024
6144 2024
6145 2024
Name: Year, Length: 6145, dtype: int64
# Datentyp Abfrage mit dem Attribut
data['Year'].dtype
dtype('O')
# Umwandlung des Datentyp
data["Year"] = pd.to_numeric(data["Year"])
data['Year'].dtype
dtype('int64')
data.columns
# Auf alle integer und float Spalten anwenden
cols = ['Total Events', 'Total Affected', 'Total Deaths', 'Total Damage (USD, original)']
for col in cols:
data[col] = pd.to_numeric(data[col])
data.info()
data.describe()
Überblick über die numerischen Daten#
data.describe()
| Year | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|
| count | 6145.00 | 6145.00 | 4962.00 | 4358.00 | 2095.00 |
| mean | 2011.90 | 1.52 | 950993.11 | 340.69 | 1716696139.34 |
| std | 7.42 | 1.28 | 8392369.40 | 5265.72 | 8615286125.55 |
| min | 2000.00 | 1.00 | 1.00 | 1.00 | 2000.00 |
| 25% | 2005.00 | 1.00 | 1003.00 | 4.00 | 20000000.00 |
| 50% | 2012.00 | 1.00 | 10000.00 | 14.00 | 130000000.00 |
| 75% | 2019.00 | 2.00 | 100552.75 | 49.00 | 801000000.00 |
| max | 2024.00 | 17.00 | 330000000.00 | 222570.00 | 210000000000.00 |
Überblick über die Objekt Daten#
Welche Länder kommen im Datensatz vor?
data['Country'].unique()
array(['Afghanistan', 'Algeria', 'Angola', 'Argentina', 'Armenia',
'Australia', 'Austria', 'Azerbaijan', 'Bangladesh', 'Belarus',
'Belize', 'Bhutan', 'Bolivia (Plurinational State of)',
'Bosnia and Herzegovina', 'Botswana', 'Brazil', 'Bulgaria',
'Burundi', 'Cambodia', 'Cameroon', 'Canada', 'Chile', 'China',
'Colombia', 'Costa Rica', 'Croatia', 'Cuba', 'Cyprus', 'Czechia',
"Democratic People's Republic of Korea", 'Ecuador', 'Egypt',
'El Salvador', 'Eswatini', 'Ethiopia', 'France', 'French Guiana',
'Georgia', 'Greece', 'Guatemala', 'Guinea', 'Haiti', 'Honduras',
'Hungary', 'Iceland', 'India', 'Indonesia',
'Iran (Islamic Republic of)', 'Ireland', 'Israel', 'Italy',
'Jamaica', 'Japan', 'Jordan', 'Kazakhstan', 'Kyrgyzstan',
"Lao People's Democratic Republic", 'Madagascar', 'Malawi',
'Malaysia', 'Mali', 'Mexico', 'Mongolia', 'Morocco', 'Mozambique',
'Namibia', 'Nepal', 'New Zealand', 'Nicaragua', 'Niger', 'Nigeria',
'North Macedonia', 'Norway', 'Pakistan', 'Panama',
'Papua New Guinea', 'Paraguay', 'Peru', 'Philippines', 'Poland',
'Portugal', 'Republic of Korea', 'Republic of Moldova', 'Romania',
'Russian Federation', 'Réunion', 'Serbia Montenegro', 'Slovakia',
'Somalia', 'South Africa', 'Spain', 'Sri Lanka', 'Sudan',
'Switzerland', 'Taiwan (Province of China)', 'Tajikistan',
'Thailand', 'Turkmenistan', 'Türkiye', 'Uganda', 'Ukraine',
'United Kingdom of Great Britain and Northern Ireland',
'United Republic of Tanzania', 'United States of America',
'Uruguay', 'Uzbekistan', 'Venezuela (Bolivarian Republic of)',
'Viet Nam', 'Zambia', 'Zimbabwe', 'Bahamas', 'Burkina Faso',
'Canary Islands', 'Cayman Islands', 'Central African Republic',
'Chad', 'Cook Islands', 'Democratic Republic of the Congo',
'Djibouti', 'Dominican Republic', 'Fiji', 'Gambia', 'Germany',
'Ghana', 'Latvia', 'Lesotho', 'Lithuania', 'Mauritania', 'Myanmar',
'Puerto Rico', 'Rwanda', 'Saint Helena', 'Samoa',
'Syrian Arab Republic', 'Timor-Leste', 'Tonga', 'Vanuatu', 'Yemen',
'Albania', 'Barbados', 'Belgium', 'Cabo Verde', 'Congo', 'Denmark',
'Grenada', 'Guam', 'Guinea-Bissau', 'Kenya', 'Lebanon',
'Mauritius', 'Micronesia (Federated States of)',
'Netherlands (Kingdom of the)', 'Northern Mariana Islands', 'Oman',
'Saint Vincent and the Grenadines', 'Saudi Arabia', 'Senegal',
'Seychelles', 'Solomon Islands', 'Sweden', 'American Samoa',
'Bermuda', 'China, Hong Kong Special Administrative Region',
'Comoros', 'Eritrea', 'Luxembourg', 'New Caledonia', 'Slovenia',
'Tunisia', 'Dominica', 'Guadeloupe', 'Maldives', 'Niue',
'Saint Lucia', 'Sierra Leone', 'Trinidad and Tobago',
'Turks and Caicos Islands', 'United States Virgin Islands',
'Estonia', 'Finland', 'Guyana', 'Tokelau', 'Iraq', 'Montserrat',
'Suriname', 'Togo', 'Benin', 'Côte d’Ivoire', 'Liberia',
'Martinique', 'Montenegro', 'Serbia', 'Antigua and Barbuda',
'Kiribati', 'Marshall Islands', 'Saint Kitts and Nevis',
'South Sudan', 'Gabon', 'French Polynesia', 'State of Palestine',
'Tuvalu', 'Palau', 'Wallis and Futuna Islands', 'Libya',
'Anguilla', 'British Virgin Islands',
'China, Macao Special Administrative Region', 'Saint Barthélemy',
'Saint Martin (French Part)', 'Sint Maarten (Dutch part)',
'United Arab Emirates', 'Kuwait', 'Qatar', 'Isle of Man',
'Sao Tome and Principe', 'Malta', 'Liechtenstein'], dtype=object)
dir(data['Country'])
['T',
'_AXIS_LEN',
'_AXIS_ORDERS',
'_AXIS_TO_AXIS_NUMBER',
'_HANDLED_TYPES',
'__abs__',
'__add__',
'__and__',
'__annotations__',
'__array__',
'__array_priority__',
'__array_ufunc__',
'__bool__',
'__class__',
'__column_consortium_standard__',
'__contains__',
'__copy__',
'__deepcopy__',
'__delattr__',
'__delitem__',
'__dict__',
'__dir__',
'__divmod__',
'__doc__',
'__eq__',
'__finalize__',
'__float__',
'__floordiv__',
'__format__',
'__ge__',
'__getattr__',
'__getattribute__',
'__getitem__',
'__getstate__',
'__gt__',
'__hash__',
'__iadd__',
'__iand__',
'__ifloordiv__',
'__imod__',
'__imul__',
'__init__',
'__init_subclass__',
'__int__',
'__invert__',
'__ior__',
'__ipow__',
'__isub__',
'__iter__',
'__itruediv__',
'__ixor__',
'__le__',
'__len__',
'__lt__',
'__matmul__',
'__mod__',
'__module__',
'__mul__',
'__ne__',
'__neg__',
'__new__',
'__nonzero__',
'__or__',
'__pandas_priority__',
'__pos__',
'__pow__',
'__radd__',
'__rand__',
'__rdivmod__',
'__reduce__',
'__reduce_ex__',
'__repr__',
'__rfloordiv__',
'__rmatmul__',
'__rmod__',
'__rmul__',
'__ror__',
'__round__',
'__rpow__',
'__rsub__',
'__rtruediv__',
'__rxor__',
'__setattr__',
'__setitem__',
'__setstate__',
'__sizeof__',
'__str__',
'__sub__',
'__subclasshook__',
'__truediv__',
'__weakref__',
'__xor__',
'_accessors',
'_accum_func',
'_agg_examples_doc',
'_agg_see_also_doc',
'_align_for_op',
'_align_frame',
'_align_series',
'_append',
'_arith_method',
'_as_manager',
'_attrs',
'_binop',
'_cacher',
'_can_hold_na',
'_check_inplace_and_allows_duplicate_labels',
'_check_is_chained_assignment_possible',
'_check_label_or_level_ambiguity',
'_check_setitem_copy',
'_clear_item_cache',
'_clip_with_one_bound',
'_clip_with_scalar',
'_cmp_method',
'_consolidate',
'_consolidate_inplace',
'_construct_axes_dict',
'_construct_result',
'_constructor',
'_constructor_expanddim',
'_constructor_expanddim_from_mgr',
'_constructor_from_mgr',
'_data',
'_deprecate_downcast',
'_dir_additions',
'_dir_deletions',
'_drop_axis',
'_drop_labels_or_levels',
'_duplicated',
'_find_valid_index',
'_flags',
'_flex_method',
'_from_mgr',
'_get_axis',
'_get_axis_name',
'_get_axis_number',
'_get_axis_resolvers',
'_get_block_manager_axis',
'_get_bool_data',
'_get_cacher',
'_get_cleaned_column_resolvers',
'_get_index_resolvers',
'_get_label_or_level_values',
'_get_numeric_data',
'_get_rows_with_mask',
'_get_value',
'_get_values_tuple',
'_get_with',
'_getitem_slice',
'_gotitem',
'_hidden_attrs',
'_indexed_same',
'_info_axis',
'_info_axis_name',
'_info_axis_number',
'_init_dict',
'_init_mgr',
'_inplace_method',
'_internal_names',
'_internal_names_set',
'_is_cached',
'_is_copy',
'_is_label_or_level_reference',
'_is_label_reference',
'_is_level_reference',
'_is_mixed_type',
'_is_view',
'_is_view_after_cow_rules',
'_item_cache',
'_ixs',
'_logical_func',
'_logical_method',
'_map_values',
'_maybe_update_cacher',
'_memory_usage',
'_metadata',
'_mgr',
'_min_count_stat_function',
'_name',
'_needs_reindex_multi',
'_pad_or_backfill',
'_protect_consolidate',
'_reduce',
'_references',
'_reindex_axes',
'_reindex_indexer',
'_reindex_multi',
'_reindex_with_indexers',
'_rename',
'_replace_single',
'_repr_data_resource_',
'_repr_latex_',
'_reset_cache',
'_reset_cacher',
'_set_as_cached',
'_set_axis',
'_set_axis_name',
'_set_axis_nocheck',
'_set_is_copy',
'_set_labels',
'_set_name',
'_set_value',
'_set_values',
'_set_with',
'_set_with_engine',
'_shift_with_freq',
'_slice',
'_stat_function',
'_stat_function_ddof',
'_take_with_is_copy',
'_to_latex_via_styler',
'_typ',
'_update_inplace',
'_validate_dtype',
'_values',
'_where',
'abs',
'add',
'add_prefix',
'add_suffix',
'agg',
'aggregate',
'align',
'all',
'any',
'apply',
'argmax',
'argmin',
'argsort',
'array',
'asfreq',
'asof',
'astype',
'at',
'at_time',
'attrs',
'autocorr',
'axes',
'backfill',
'between',
'between_time',
'bfill',
'bool',
'case_when',
'clip',
'combine',
'combine_first',
'compare',
'convert_dtypes',
'copy',
'corr',
'count',
'cov',
'cummax',
'cummin',
'cumprod',
'cumsum',
'describe',
'diff',
'div',
'divide',
'divmod',
'dot',
'drop',
'drop_duplicates',
'droplevel',
'dropna',
'dtype',
'dtypes',
'duplicated',
'empty',
'eq',
'equals',
'ewm',
'expanding',
'explode',
'factorize',
'ffill',
'fillna',
'filter',
'first',
'first_valid_index',
'flags',
'floordiv',
'ge',
'get',
'groupby',
'gt',
'hasnans',
'head',
'hist',
'iat',
'idxmax',
'idxmin',
'iloc',
'index',
'infer_objects',
'info',
'interpolate',
'is_monotonic_decreasing',
'is_monotonic_increasing',
'is_unique',
'isin',
'isna',
'isnull',
'item',
'items',
'keys',
'kurt',
'kurtosis',
'last',
'last_valid_index',
'le',
'list',
'loc',
'lt',
'map',
'mask',
'max',
'mean',
'median',
'memory_usage',
'min',
'mod',
'mode',
'mul',
'multiply',
'name',
'nbytes',
'ndim',
'ne',
'nlargest',
'notna',
'notnull',
'nsmallest',
'nunique',
'pad',
'pct_change',
'pipe',
'plot',
'pop',
'pow',
'prod',
'product',
'quantile',
'radd',
'rank',
'ravel',
'rdiv',
'rdivmod',
'reindex',
'reindex_like',
'rename',
'rename_axis',
'reorder_levels',
'repeat',
'replace',
'resample',
'reset_index',
'rfloordiv',
'rmod',
'rmul',
'rolling',
'round',
'rpow',
'rsub',
'rtruediv',
'sample',
'searchsorted',
'sem',
'set_axis',
'set_flags',
'shape',
'shift',
'size',
'skew',
'sort_index',
'sort_values',
'squeeze',
'std',
'str',
'struct',
'sub',
'subtract',
'sum',
'swapaxes',
'swaplevel',
'tail',
'take',
'to_clipboard',
'to_csv',
'to_dict',
'to_excel',
'to_frame',
'to_hdf',
'to_json',
'to_latex',
'to_list',
'to_markdown',
'to_numpy',
'to_period',
'to_pickle',
'to_sql',
'to_string',
'to_timestamp',
'to_xarray',
'transform',
'transpose',
'truediv',
'truncate',
'tz_convert',
'tz_localize',
'unique',
'unstack',
'update',
'value_counts',
'values',
'var',
'view',
'where',
'xs']
# Unterschiedliche Länder
countries = data['Country'].unique()
countries
len(countries)
sorted(countries)
['Afghanistan',
'Albania',
'Algeria',
'American Samoa',
'Angola',
'Anguilla',
'Antigua and Barbuda',
'Argentina',
'Armenia',
'Australia',
'Austria',
'Azerbaijan',
'Bahamas',
'Bangladesh',
'Barbados',
'Belarus',
'Belgium',
'Belize',
'Benin',
'Bermuda',
'Bhutan',
'Bolivia (Plurinational State of)',
'Bosnia and Herzegovina',
'Botswana',
'Brazil',
'British Virgin Islands',
'Bulgaria',
'Burkina Faso',
'Burundi',
'Cabo Verde',
'Cambodia',
'Cameroon',
'Canada',
'Canary Islands',
'Cayman Islands',
'Central African Republic',
'Chad',
'Chile',
'China',
'China, Hong Kong Special Administrative Region',
'China, Macao Special Administrative Region',
'Colombia',
'Comoros',
'Congo',
'Cook Islands',
'Costa Rica',
'Croatia',
'Cuba',
'Cyprus',
'Czechia',
'Côte d’Ivoire',
"Democratic People's Republic of Korea",
'Democratic Republic of the Congo',
'Denmark',
'Djibouti',
'Dominica',
'Dominican Republic',
'Ecuador',
'Egypt',
'El Salvador',
'Eritrea',
'Estonia',
'Eswatini',
'Ethiopia',
'Fiji',
'Finland',
'France',
'French Guiana',
'French Polynesia',
'Gabon',
'Gambia',
'Georgia',
'Germany',
'Ghana',
'Greece',
'Grenada',
'Guadeloupe',
'Guam',
'Guatemala',
'Guinea',
'Guinea-Bissau',
'Guyana',
'Haiti',
'Honduras',
'Hungary',
'Iceland',
'India',
'Indonesia',
'Iran (Islamic Republic of)',
'Iraq',
'Ireland',
'Isle of Man',
'Israel',
'Italy',
'Jamaica',
'Japan',
'Jordan',
'Kazakhstan',
'Kenya',
'Kiribati',
'Kuwait',
'Kyrgyzstan',
"Lao People's Democratic Republic",
'Latvia',
'Lebanon',
'Lesotho',
'Liberia',
'Libya',
'Liechtenstein',
'Lithuania',
'Luxembourg',
'Madagascar',
'Malawi',
'Malaysia',
'Maldives',
'Mali',
'Malta',
'Marshall Islands',
'Martinique',
'Mauritania',
'Mauritius',
'Mexico',
'Micronesia (Federated States of)',
'Mongolia',
'Montenegro',
'Montserrat',
'Morocco',
'Mozambique',
'Myanmar',
'Namibia',
'Nepal',
'Netherlands (Kingdom of the)',
'New Caledonia',
'New Zealand',
'Nicaragua',
'Niger',
'Nigeria',
'Niue',
'North Macedonia',
'Northern Mariana Islands',
'Norway',
'Oman',
'Pakistan',
'Palau',
'Panama',
'Papua New Guinea',
'Paraguay',
'Peru',
'Philippines',
'Poland',
'Portugal',
'Puerto Rico',
'Qatar',
'Republic of Korea',
'Republic of Moldova',
'Romania',
'Russian Federation',
'Rwanda',
'Réunion',
'Saint Barthélemy',
'Saint Helena',
'Saint Kitts and Nevis',
'Saint Lucia',
'Saint Martin (French Part)',
'Saint Vincent and the Grenadines',
'Samoa',
'Sao Tome and Principe',
'Saudi Arabia',
'Senegal',
'Serbia',
'Serbia Montenegro',
'Seychelles',
'Sierra Leone',
'Sint Maarten (Dutch part)',
'Slovakia',
'Slovenia',
'Solomon Islands',
'Somalia',
'South Africa',
'South Sudan',
'Spain',
'Sri Lanka',
'State of Palestine',
'Sudan',
'Suriname',
'Sweden',
'Switzerland',
'Syrian Arab Republic',
'Taiwan (Province of China)',
'Tajikistan',
'Thailand',
'Timor-Leste',
'Togo',
'Tokelau',
'Tonga',
'Trinidad and Tobago',
'Tunisia',
'Turkmenistan',
'Turks and Caicos Islands',
'Tuvalu',
'Türkiye',
'Uganda',
'Ukraine',
'United Arab Emirates',
'United Kingdom of Great Britain and Northern Ireland',
'United Republic of Tanzania',
'United States Virgin Islands',
'United States of America',
'Uruguay',
'Uzbekistan',
'Vanuatu',
'Venezuela (Bolivarian Republic of)',
'Viet Nam',
'Wallis and Futuna Islands',
'Yemen',
'Zambia',
'Zimbabwe']
# Vorkommen von Ländern der Liste
'Vietnam' in countries
False
# Vorkommen von Deutschland
for country in countries:
if 'german' in country.lower():
print(country)
Was sind die unterschiedlichen Katastrophentypen?#
data.columns
Index(['Year', 'Country', 'Disaster Subroup', 'Disaster Type',
'Disaster Subtype', 'Total Events', 'Total Affected', 'Total Deaths',
'Total Damage (USD, original)'],
dtype='object')
data['Disaster Type'].unique()
['Animal incident',
'Drought',
'Earthquake',
'Extreme temperature',
'Flood',
'Glacial lake outburst flood',
'Impact',
'Infestation',
'Mass movement (dry)',
'Mass movement (wet)',
'Storm',
'Volcanic activity',
'Wildfire']
.value_counts() zeigt wie oft eine Spalte die unterschiedlichen Werte annimmt.
data['Country'].value_counts()
Country
United States of America 247
China 216
India 174
Indonesia 146
Philippines 121
...
Tokelau 1
Niue 1
Bermuda 1
Saint Helena 1
Liechtenstein 1
Name: count, Length: 217, dtype: int64
data['Disaster Type'].value_counts()
Disaster Type
Flood 2482
Storm 1620
Extreme temperature 489
Drought 403
Earthquake 400
Mass movement (wet) 346
Wildfire 246
Volcanic activity 110
Infestation 29
Mass movement (dry) 14
Glacial lake outburst flood 4
Impact 1
Animal incident 1
Name: count, dtype: int64
Mit dem Argument normalize=True wird das Vorkommen der Werte automatisch ins Verhältnis gesetzt.
data['Disaster Type'].value_counts(normalize=True)
Disaster Type
Flood 0.40
Storm 0.26
Extreme temperature 0.08
Drought 0.07
Earthquake 0.07
Mass movement (wet) 0.06
Wildfire 0.04
Volcanic activity 0.02
Infestation 0.00
Mass movement (dry) 0.00
Glacial lake outburst flood 0.00
Impact 0.00
Animal incident 0.00
Name: proportion, dtype: float64
Dataframes Sortieren#
Dataframes können anhand einer oder meherer Spalten sortiert werden.
Bei welchen Katastrophe waren am meisten Menschen betroffen?
Welche Naturkatastrophen waren am tödlichsten?
data.sort_values(by="Total Affected", ascending=False)
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 3752 | 2015 | India | Climatological | Drought | Drought | 1 | 330000000.00 | NaN | 3000000000.00 |
| 647 | 2002 | India | Climatological | Drought | Drought | 1 | 300000000.00 | NaN | 910722000.00 |
| 878 | 2003 | China | Hydrological | Flood | Riverine flood | 6 | 155924986.00 | 662.00 | 15329640000.00 |
| 2605 | 2010 | China | Hydrological | Flood | Riverine flood | 5 | 140194136.00 | 1911.00 | 18171000000.00 |
| 1894 | 2007 | China | Hydrological | Flood | Riverine flood | 9 | 108793242.00 | 967.00 | 4919155000.00 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 6105 | 2024 | Switzerland | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 6.00 | NaN |
| 6114 | 2024 | Türkiye | Climatological | Wildfire | Wildfire (General) | 1 | NaN | NaN | NaN |
| 6120 | 2024 | United Arab Emirates | Hydrological | Flood | Flash flood | 1 | NaN | 4.00 | NaN |
| 6125 | 2024 | United Republic of Tanzania | Hydrological | Mass movement (wet) | Landslide (wet) | 1 | NaN | 22.00 | NaN |
| 6130 | 2024 | United States of America | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | 61.00 | 3800000000.00 |
6145 rows × 9 columns
data.sort_values(by="Total Affected", ascending=False).head(10)
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 3752 | 2015 | India | Climatological | Drought | Drought | 1 | 330000000.00 | NaN | 3000000000.00 |
| 647 | 2002 | India | Climatological | Drought | Drought | 1 | 300000000.00 | NaN | 910722000.00 |
| 878 | 2003 | China | Hydrological | Flood | Riverine flood | 6 | 155924986.00 | 662.00 | 15329640000.00 |
| 2605 | 2010 | China | Hydrological | Flood | Riverine flood | 5 | 140194136.00 | 1911.00 | 18171000000.00 |
| 1894 | 2007 | China | Hydrological | Flood | Riverine flood | 9 | 108793242.00 | 967.00 | 4919155000.00 |
| 589 | 2002 | China | Meteorological | Storm | Sand/Dust storm | 1 | 100000000.00 | NaN | NaN |
| 2863 | 2011 | China | Hydrological | Flood | Riverine flood | 5 | 93360000.00 | 628.00 | 10704130000.00 |
| 4099 | 2016 | United States of America | Meteorological | Storm | Blizzard/Winter storm | 4 | 85000057.00 | 90.00 | 2125000000.00 |
| 583 | 2002 | China | Hydrological | Flood | Flash flood | 1 | 80035257.00 | 793.00 | 3100000000.00 |
| 2152 | 2008 | China | Meteorological | Extreme temperature | Severe winter conditions | 2 | 77000000.00 | 145.00 | 21100000000.00 |
data.sort_values(by="Total Deaths", ascending=False).head(10)
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 2661 | 2010 | Haiti | Geophysical | Earthquake | Ground movement | 1 | 3700000.00 | 222570.00 | 8000000000.00 |
| 1164 | 2004 | Indonesia | Geophysical | Earthquake | Tsunami | 1 | 532898.00 | 165708.00 | 4451600000.00 |
| 2250 | 2008 | Myanmar | Meteorological | Storm | Tropical cyclone | 1 | 2420000.00 | 138366.00 | 4000000000.00 |
| 2148 | 2008 | China | Geophysical | Earthquake | Ground movement | 7 | 47369797.00 | 87564.00 | 85492000000.00 |
| 1497 | 2005 | Pakistan | Geophysical | Earthquake | Ground movement | 1 | 5128309.00 | 73338.00 | 5200000000.00 |
| 2761 | 2010 | Russian Federation | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 55736.00 | 400000000.00 |
| 5882 | 2023 | Türkiye | Geophysical | Earthquake | Ground movement | 3 | 16107494.00 | 53007.00 | 34000000000.00 |
| 1270 | 2004 | Sri Lanka | Geophysical | Earthquake | Tsunami | 1 | 1019306.00 | 35399.00 | 1316500000.00 |
| 945 | 2003 | Iran (Islamic Republic of) | Geophysical | Earthquake | Ground movement | 5 | 297049.00 | 26797.00 | 521666000.00 |
| 950 | 2003 | Italy | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 20089.00 | 4400000000.00 |
# Mehrere Argumente zum Sortieren sind möglich
data.sort_values(by=["Disaster Subroup", "Total Affected"], ascending=[False, True]).head(n=10)
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 1488 | 2005 | Netherlands (Kingdom of the) | Meteorological | Storm | Extra-tropical storm | 1 | 1.00 | NaN | NaN |
| 3238 | 2012 | United States of America | Meteorological | Storm | Blizzard/Winter storm | 3 | 1.00 | 27.00 | 202000000.00 |
| 3502 | 2014 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 2 | 1.00 | 8.00 | 400000000.00 |
| 5029 | 2020 | Taiwan (Province of China) | Meteorological | Storm | Tropical cyclone | 1 | 1.00 | 1.00 | NaN |
| 5988 | 2024 | France | Meteorological | Storm | Extra-tropical storm | 1 | 1.00 | 8.00 | NaN |
| 225 | 2000 | Spain | Meteorological | Storm | Storm (General) | 2 | 2.00 | 14.00 | NaN |
| 784 | 2002 | Switzerland | Meteorological | Storm | Storm (General) | 1 | 2.00 | 1.00 | NaN |
| 1419 | 2005 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | 2.00 | 2.00 | 270000000.00 |
| 1530 | 2005 | Russian Federation | Meteorological | Storm | Extra-tropical storm | 1 | 2.00 | NaN | NaN |
| 1861 | 2007 | Belgium | Meteorological | Storm | Extra-tropical storm | 1 | 2.00 | 2.00 | 450000000.00 |
Analyse einzelner Aspekte durch Filtern von Daten#
Wie viele Naturkatastrophen gab es in Deutschland seit 2000?
Welchen Anteil haben Stürme?
Wie viele Menschen sind jedes Jahr betroffen?
Um diese Fragen zu beantworten filtern wir die Daten auf Deutschland und berechnen Statistiken.
Siehe auch:
data['Country']
1 Afghanistan
2 Algeria
3 Algeria
4 Angola
5 Angola
...
6141 Viet Nam
6142 Yemen
6143 Yemen
6144 Zambia
6145 Zimbabwe
Name: Country, Length: 6145, dtype: object
data[data['Country'] == 'Germany']
| Year | Country | Disaster Subroup | Disaster Type | Disaster Subtype | Total Events | Total Affected | Total Deaths | Total Damage (USD, original) | |
|---|---|---|---|---|---|---|---|---|---|
| 365 | 2001 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 1 | NaN | 6.00 | 300000000.00 |
| 626 | 2002 | Germany | Hydrological | Flood | Flood (General) | 1 | 330108.00 | 27.00 | 11600000000.00 |
| 627 | 2002 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 11.00 | 1800000000.00 |
| 628 | 2002 | Germany | Meteorological | Storm | Storm (General) | 2 | 19.00 | 11.00 | 250000000.00 |
| 915 | 2003 | Germany | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 9355.00 | 1650000000.00 |
| 916 | 2003 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 5.00 | 300000000.00 |
| 917 | 2003 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 1 | NaN | 10.00 | NaN |
| 1148 | 2004 | Germany | Geophysical | Earthquake | Ground movement | 1 | 150.00 | NaN | 12000000.00 |
| 1149 | 2004 | Germany | Meteorological | Storm | Storm (General) | 1 | NaN | 2.00 | 130000000.00 |
| 1417 | 2005 | Germany | Hydrological | Flood | Riverine flood | 2 | 450.00 | 1.00 | 220000000.00 |
| 1418 | 2005 | Germany | Meteorological | Extreme temperature | Cold wave | 1 | 165.00 | 1.00 | 300000000.00 |
| 1419 | 2005 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | 2.00 | 2.00 | 270000000.00 |
| 1677 | 2006 | Germany | Hydrological | Flood | Riverine flood | 1 | 1000.00 | NaN | NaN |
| 1678 | 2006 | Germany | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 2.00 | NaN |
| 1679 | 2006 | Germany | Meteorological | Extreme temperature | Severe winter conditions | 1 | NaN | 10.00 | NaN |
| 1680 | 2006 | Germany | Meteorological | Storm | Hail | 1 | 100.00 | 1.00 | NaN |
| 1681 | 2006 | Germany | Meteorological | Storm | Storm (General) | 2 | 200.00 | 10.00 | NaN |
| 1931 | 2007 | Germany | Hydrological | Flood | Riverine flood | 1 | NaN | 1.00 | NaN |
| 1932 | 2007 | Germany | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | 7.00 | NaN |
| 1933 | 2007 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | 130.00 | 11.00 | 5500000000.00 |
| 2187 | 2008 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 5.00 | 1200000000.00 |
| 2188 | 2008 | Germany | Meteorological | Storm | Severe weather | 1 | NaN | 3.00 | 1500000000.00 |
| 2415 | 2009 | Germany | Hydrological | Flood | Riverine flood | 1 | NaN | NaN | 20000000.00 |
| 2416 | 2009 | Germany | Meteorological | Extreme temperature | Cold wave | 2 | NaN | 15.00 | NaN |
| 2417 | 2009 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 1 | NaN | 1.00 | 50000000.00 |
| 2647 | 2010 | Germany | Hydrological | Flood | Flash flood | 1 | NaN | 3.00 | NaN |
| 2648 | 2010 | Germany | Meteorological | Extreme temperature | Cold wave | 1 | NaN | 1.00 | NaN |
| 2649 | 2010 | Germany | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | NaN | NaN |
| 2650 | 2010 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 4.00 | 1000000000.00 |
| 3103 | 2012 | Germany | Meteorological | Extreme temperature | Cold wave | 2 | NaN | 6.00 | NaN |
| 3309 | 2013 | Germany | Hydrological | Flood | Riverine flood | 1 | 6350.00 | 4.00 | 12900000000.00 |
| 3310 | 2013 | Germany | Meteorological | Storm | Extra-tropical storm | 2 | 2.00 | 7.00 | NaN |
| 3311 | 2013 | Germany | Meteorological | Storm | Hail | 1 | NaN | NaN | 4800000000.00 |
| 3502 | 2014 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 2 | 1.00 | 8.00 | 400000000.00 |
| 3960 | 2016 | Germany | Hydrological | Flood | Flood (General) | 1 | NaN | 7.00 | 2000000000.00 |
| 4192 | 2017 | Germany | Hydrological | Flood | Riverine flood | 1 | 600.00 | NaN | NaN |
| 4193 | 2017 | Germany | Meteorological | Storm | Hail | 1 | NaN | 2.00 | 740000000.00 |
| 4194 | 2017 | Germany | Meteorological | Storm | Severe weather | 1 | 24.00 | 3.00 | 159000000.00 |
| 4421 | 2018 | Germany | Meteorological | Extreme temperature | Heat wave | 1 | NaN | NaN | NaN |
| 4422 | 2018 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | 12.00 | 5.00 | 588475000.00 |
| 4667 | 2019 | Germany | Meteorological | Extreme temperature | Heat wave | 2 | NaN | 4.00 | NaN |
| 4668 | 2019 | Germany | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | 1.00 | NaN |
| 4907 | 2020 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | 33.00 | NaN | NaN |
| 5167 | 2021 | Germany | Hydrological | Flood | Flood (General) | 1 | 1000.00 | 226.00 | 40000000000.00 |
| 5168 | 2021 | Germany | Meteorological | Storm | Lightning/Thunderstorms | 1 | 600.00 | NaN | NaN |
| 5169 | 2021 | Germany | Meteorological | Storm | Storm (General) | 1 | 4.00 | 1.00 | NaN |
| 5434 | 2022 | Germany | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 8173.00 | NaN |
| 5435 | 2022 | Germany | Meteorological | Storm | Extra-tropical storm | 3 | 2.00 | 7.00 | 1023156000.00 |
| 5716 | 2023 | Germany | Meteorological | Extreme temperature | Heat wave | 1 | NaN | 6376.00 | NaN |
| 5717 | 2023 | Germany | Meteorological | Storm | Blizzard/Winter storm | 1 | NaN | 2.00 | NaN |
| 5718 | 2023 | Germany | Meteorological | Storm | Extra-tropical storm | 1 | NaN | 1.00 | NaN |
| 5719 | 2023 | Germany | Meteorological | Storm | Severe weather | 1 | NaN | 1.00 | NaN |
| 5990 | 2024 | Germany | Hydrological | Flood | Flood (General) | 1 | 3407.00 | 12.00 | 5400000000.00 |
data[data['Country'] == 'Germany']
german_data = data[data['Country'] == 'Germany']
german_data.head(5)
Aufgaben#
Wie viele Naturkatastrophen gab es in Deutschland seit 2000?
Wann und was waren die schlimmsten Naturkatastrophen in Deutschland?
Wie viele Menschen waren insgesamt in Deutschland von Naturkatastrophen betroffen?
Wie viele Menschen sind 2024 in Deutschland bei Naturkatastrophen ums Leben gekommen?
Bei welchen Katastrophen in Deutschland starben mehr als 15 Personen?
Wie oft kommen die einzelnen Naturkatastrophentypen in Deutschland vor?
Groupby#
Die groupby-Funktion in Pandas wird verwendet, um Daten in Gruppen basierend auf einem oder mehreren Spaltenwerten zu organisieren. Auf diesen Gruppen können dann weitere Funktionen wie Berechnungen oder Transformationen angewendet werden.
Der Ablauf#
Gruppieren: Daten werden nach bestimmten Spaltenwerten gruppiert.
Anwenden: Auf jede Gruppe wird eine Operation (z. B. sum, mean, count) angewendet.
Kombinieren: Die Ergebnisse werden in einem neuen DataFrame oder Series zusammengefasst.
Wie viele Menschen waren je Naturkatastrophentyp in Deutschland betroffen?
german_data.groupby(['Disaster Type'])['Total Affected'].sum()
Wie viele Menschen sind pro Jahr von Naturkatastrophen betroffen?
german_data.groupby(['Year'])['Total Affected'].sum()
Wie viele Menschen sind in Deutschland pro Jahr und Katastrophentyp betroffen?
german_data.groupby(['Year', 'Disaster Type'])['Total Deaths'].sum()